K-12 Standards and Assessments
OVERVIEW
Now is the time to begin to rethink how we assess learning for the challenges of the digital world that lie ahead. In elementary and middle school, the curriculum is mastery-based, meaning students must score 80 percent or higher on an assessment before moving on to the next learning objective. Short answer or multiple choice assessments are given at the end of most lessons in K-8 and are administered and recorded. In high school, teachers monitor student’s progress and grade tests and assignments.
Some people oppose the use of standardized testing, or any type of testing, to determine educational quality. They prefer alternatives such as teacher opinions, classwork, and performance-based assessments.
Every Student Succeeds Act, schools are held almost exclusively accountable for absolute levels of student performance. But that meant that even schools that were making great strides with students were still labeled as “failing” just because the students had not yet made it all the way to a “proficient” level of achievement. Since 2005, the U.S. Department of Education has approved 15 states to implement growth model pilots. Each state adopted one of four distinct growth models: Trajectory, Transition Tables, Student Growth Percentiles, and Projection.
The incentives for improvement also may cause states to lower their official standards. Because each state can produce its own standardized tests, a state can make its statewide tests easier to increase scores. Missouri, for example, improved testing scores but openly admitted that they lowered the standards. A 2007 study by the U.S. Dept. of Education indicates that the observed differences in states’ reported scores is largely due to differences in the stringency of their standards.
Presumably, states that move to CCSS will continue to assess using tests designed for their old state standards until the CCSS assessments are released, with the result that during the transition there will be confusion for publishers attempting to create materials targeting assessments. Finding the right mix of standards alignment—whether to existing state standards or to the Common Core—is one more factor that needs to be attended to in designing useful learning supplements for schools. But, the eventual establishment of a single set of standards for all states and the subsequent process of aligning content to one set of standards will lower the cost of entry and open the market to smaller companies.
The process approach to education is requiring new forms of student assessment. In addition to standardize assessment students will demonstrate their skills, assess their own learning, and evaluate the processes by which this learning has been achieved by preparing portfolios, learning and research logs, and using rubrics.
As the focus of problem based learning centers on a specific problem, academic achievement scores often favor traditional teaching methods when standardized tests are used, but favor neither method when non-standardized forms of assessment are employed. These measures include problem-solving ability, interpersonal skills, peer-tutor relationships, the ability to reason, and self-motivated learning. In contrast, traditional instruction is judged better in the coverage of science content areas and in evaluating students’ knowledge content. Although problem based learning tends to reduce initial levels of learning, it can improve long-term retention (see: K-12 Learning & Teaching Platforms/Concept Mapping).
We should be solving real problems, asking questions that matter instead of remembering and repeating facts. Adults’ accomplishments are linked far more strongly to their creativity than IQ (source) and we should be celebrating diverse knowledge and interest instead of trying to standardize knowledge and skills. I wonder if schools would finally change their direction if we designed a new standardize test that wouldn’t measure numeracy, science and literacy but empathy, creative thinking and communication skills… Maybe that is all we need. (Omarsson, 2014)
In Cathy Davidson’s article (see end of this section) “Standardize Tests? In the Internet Age, that’s the wrong Answer,” When Frederick J. Kelly invented the multiple-choice test in 1914, he was addressing a national crisis. Because of immigration the number of secondary students had jumped from 200,000 in 1890 to more than 1.5 million. In addition, a new law made two years of high school for every one mandatory. The country needed to process students quickly and efficiently. Kelly wrote in his dissertation at Kansas State Teachers College, to streamline schooling. What he came up with was the “Kansas Silent Reading Test”, aka the “bubble” test.
 Today, American public school students are still taking versions of Kelly’s test. End-of-grade exams, required under the No Child Left Behind law, are modeled after his idea: Fill in the circles. There is only one right answer. Stop when time is called. These antiquated standardized tests are still serving as the backbone for measuring achievement. Our students can’t escape Kelly’s century-old invention.
Today, American public school students are still taking versions of Kelly’s test. End-of-grade exams, required under the No Child Left Behind law, are modeled after his idea: Fill in the circles. There is only one right answer. Stop when time is called. These antiquated standardized tests are still serving as the backbone for measuring achievement. Our students can’t escape Kelly’s century-old invention.
“School” is evolutionary but the multiple-choice exam, which has not, has had an impact far beyond the crisis that inspired it, and a reach and application far beyond what its inventor intended. From his papers at the University of Idaho, it is clear that Kelly didn’t mean for standardized testing to become so widespread. Although he argued for uniform ways of judging achievement, he also indicated that his Kansas Silent Reading Test was intended to measure “lower-order thinking” among the masses (which were then called the “lower orders”). But this form of testing is, of course, now the gold standard for just about everything, from No Child Left Behind tests to college entrance exams to tests for graduate and professional schools.
After WWII, Kelly himself began to ardently champion a different direction for educational reform, a model of liberal, integrated, problem-based learning. In his inaugural address as University of Idaho president in 1928, he argued for expansive changes almost diametrically opposite to his early advocacy of standardized testing stating, “College is a place to learn how to educate oneself rather than a place in which to be educated.”
Too late. By then, the College Entrance Examination Board had adopted Kelly’s test as the basis for its “Scholastic Aptitude Test” (SAT). Business schools and schools of education were using item-response testing as the new metric for measuring success. Kelly’s faculty was furious that the inventor of the bubble test now advocated a different course, and he was asked to step down as president barely two years later.
Kelly couldn’t get rid of the test he created, but we should be able to. Institutions of education should be preparing our kids for their future — not for our past. In the Internet age, we are saddled with an educational system that was designed for the industrial age, modeled on mass production and designed for efficiency, not for high standards.
A standard test question for young students today, dating back to Kelly’s original exam, is which of four animals is a farm animal (a cow, a tiger, a rat or a wolf). The same child who flubs this question can go to, Google “farm animals” and get 14.8 million results. What part of our educational system prepares a student to sort through and evaluate all those Web sites? Multiple-choice exams do not equip kids for either the information avalanche or the fine print that they encounter online every day.
In a decade of researching digital education, I have never heard an educator, parent or student say that the tests work well as teaching tools. Beyond the flaws of these rigid exams — which do not measure complex, connected, interactive skills — there is little room in the current curriculum or even in the current division of disciplines (reading, writing, math, natural sciences and social studies) for lessons about key questions that affect students’ daily lives. Teaching kids about credibility, security, privacy, intellectual property and other bases of their online lives, after all, would take time away from the tested subjects that lead to merits or demerits, funding or reduced funding, depending on exam scores. Yet every school curriculum should include interactive lessons in practical, creative and cautious participation in the World Wide Web. Ideally, students should be learning these lessons even as they learn the basics of code.
INTERNATIONAL STANDARDIZED TESTS
(The following is an abstract from “American 15-year-olds Lag, Mainly in Math, on international Standardized Test” by Motoko Rich – NY Times 12/3/2013)
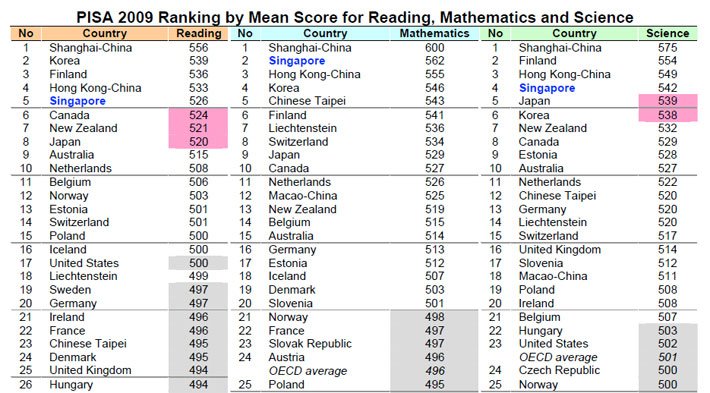
Every four years The Program for International Student Assessment (PISA) is administered to 15-ywar-olds in 65 countries and school systems by the organization for Economic Cooperation and Development, a Paris-based group that includes the world’s wealthiest nations. The U.S. 6,100 fifteen-year-olds who took the test scored in the middle of the developed world in reading and science while lagging in math. The results were similar to those in 2009 the last time the test was administered. Shanghai, Hong Kong, Singapore, Japan and South Korea were that the top, again.
Development, a Paris-based group that includes the world’s wealthiest nations. The U.S. 6,100 fifteen-year-olds who took the test scored in the middle of the developed world in reading and science while lagging in math. The results were similar to those in 2009 the last time the test was administered. Shanghai, Hong Kong, Singapore, Japan and South Korea were that the top, again.
The U.S. underperformance was particularly striking in math where 29 counties or education systems had higher scores. In science students in 22 countries did better than Americans, and in reading, 19 countries. In the U.S. just nine percent of the 15-year-olds scored in the top two levels of proficiency in math, compared with an average of 13% among industrialized nations and as high as 55 percent in Shanghai, 40 percent in Singapore, and 17 percent in Germany and Poland.
A reprehensive of the National Education Association, the nation’s largest teacher’s union, blamed the low scores on that fact the U.S. has not done enough to address poverty. However, the National Center for Education Statistics said American students from families with incomes in the highest quartile did not perform as well as students with similar backgrounds in other counties.
 One economist felt that the U.S. has been able to overcome the deficiencies in our educational system because of our strong economy but he said that if we don’t improve we are going to be slipping. However one research associate felt that educators and academics should stop worrying about international test rankings, particularly given that students are already graduating from college at a higher rate than can be absorbed by the labor market.
One economist felt that the U.S. has been able to overcome the deficiencies in our educational system because of our strong economy but he said that if we don’t improve we are going to be slipping. However one research associate felt that educators and academics should stop worrying about international test rankings, particularly given that students are already graduating from college at a higher rate than can be absorbed by the labor market.
The National Center on Education and the Economy, a nonprofit think tank, felt that by trying to reform education by using student test scores to evaluate teacher will be turning graduates off from becoming teachers and many parents are objecting to a focus on standardized test at the expense of values like creativity. The Thomas B. Fordham Institute, a conservative education policy group feels that there is no reason why we can’t keep the creativity while also teaching kids how to do math better.
K-12 U.S. ASSESSMENT
Analyses of the state accountability systems that were in place before NCLB, indicates that accountability for outcomes led to faster growth in achievement for the states that introduced such systems. The direct analysis of state test scores before and after enactment of NCLB also supports its positive impact. A primary criticism asserts that NCLB reduces effective instruction and student learning by causing states to lower achievement goals and motivate teachers to “teach to the test.” A primary supportive claim asserts that systematic testing provides data that shed light on which schools are not teaching basic skills effectively, so that interventions can be made to improve outcomes for all students while reducing the achievement gap for disadvantaged and disabled students.
The direct analysis of state test scores before and after enactment of NCLB also supports its positive impact. A primary criticism asserts that NCLB reduces effective instruction and student learning by causing states to lower achievement goals and motivate teachers to “teach to the test.” A primary supportive claim asserts that systematic testing provides data that shed light on which schools are not teaching basic skills effectively, so that interventions can be made to improve outcomes for all students while reducing the achievement gap for disadvantaged and disabled students.
COMMON CORE ASSESSMENT
 With the implementation of new standards, states are also required to adopt new assessment benchmarks to measure student achievement. According to the Common Core State Standards Initiative website, formal assessment is expected to take place in the 2014–2015 school year, which coincides with the projected implementation year for most states. The new computer-based assessment has yet to be created, but the two consortiums (PARCC and SBAC) were generated with two different approaches as to how to assess the standards. PARCC’s approach will focus on computer-based ‘through-course assessments’ in each grade combined with streamlined end of year tests, including performance tasks while SBAC will create adaptive online exams. The final decision of which assessment to use will be determined by individual state education agencies.
With the implementation of new standards, states are also required to adopt new assessment benchmarks to measure student achievement. According to the Common Core State Standards Initiative website, formal assessment is expected to take place in the 2014–2015 school year, which coincides with the projected implementation year for most states. The new computer-based assessment has yet to be created, but the two consortiums (PARCC and SBAC) were generated with two different approaches as to how to assess the standards. PARCC’s approach will focus on computer-based ‘through-course assessments’ in each grade combined with streamlined end of year tests, including performance tasks while SBAC will create adaptive online exams. The final decision of which assessment to use will be determined by individual state education agencies.
Testing remains a significant revenue source for the big companies under Common Core. CTB/McGraw-Hill has won multiple contracts to help develop questions for Common Core tests. In 2011, Pearson won a $32 million contract to develop New York’s standardized tests, a contract that runs through 2015.
 Both PARCC and SBAC are proposing computer-based exams that include fewer selected and constructed response test items, which moves away from what we typically think of as the Standardized Tests most students are currently taking. Some states plan to work together to create a common, universal assessment system based on the common core state standards while other states are choosing to work independently or through the consortiums to develop the assessment.
Both PARCC and SBAC are proposing computer-based exams that include fewer selected and constructed response test items, which moves away from what we typically think of as the Standardized Tests most students are currently taking. Some states plan to work together to create a common, universal assessment system based on the common core state standards while other states are choosing to work independently or through the consortiums to develop the assessment.
According to policy analysts, the goal of increased exposure to informational texts and literary nonfiction in Common Core is to have students read challenging texts that will build their vocabulary and background knowledge. As a student progresses through the grades, the nonfiction proportion of materials should increase until it represents 70 percent of total reading in all classes. However English teachers “are not required to devote 70 percent of reading to informational texts.” The standards require certain critical content for all students, including: classic myths and stories from around the world, America’s Founding Documents, foundational American literature, and Shakespeare. The consortia are focusing assessment on the following principles:
- Allow for comparison across students, schools, districts, states and nations;
- Create economies of scale;
- Provide information and support more effective teaching and learning; and
- Prepare students for college and careers.
NATIONAL STANDARDS
Common Core marks the first time multiple states will have the same standards and tests, with the exception of a few New England states. National tests are necessary because the current system of federal mandates encourages states to lower their standards in order to look better.
The system is currently set up so the states typically reach for the bottom, testing for the lower third. This is because if a state has lower scores than a neighboring state they can make their tests easier. It is very difficult to compare one state to another because of multiple standards and tests so offering the same test with advanced and proficient questions is essential for balanced comparability. The more states that participate the better the comparison data will be.
The National Assessment of Educational Progress is an existing way to judge states and school districts using the exact same nationwide measures. Critics say that national standards and tests foolishly assume that there is only one way to educate all children, and that we know what it is. More than people realize, testing is a complex activity and test writers have to consider how many questions, how difficult, and should the questions change as the student progresses to offer harder or easier questions, or should every student get the same questions? How do we differentiate between the super smart kids? They might get all the answers right, but we won’t know exactly what they know so should be ask more questions?
The way Common Core assessments measure students will be unique. It will be difficult to make a similar test.
FAILURE IS A GOOD THING
Because of the more rigorous K-12 curriculum and testing test scores are predicted to drop by as much as 30% in states that lowered their assessment standards as has been the case and a point of controversy in pilot states.
This is not necessarily a bad thing as several positive results will happen. First, the student will be rigorously challenged by the test and the student will experience failure. The first is an expectation of the Common Core Initiative and the second is a common complaint by employers of students entering the work force.
With this Innovative-based Learning method of assessment the student is allowed to take three tests related to the same subject. The tests are used as learning-aids similar to the way Blended-based Learning works. A students’ proficiency will improve over time if they are afforded regular opportunities to learn, apply the skills they have learned and not be afraid of the testing process. (see: K-12 Learning & Teaching Platforms/Innovative-based Learning)
New Standards Testing Concerns
(The following is an abstract from Sarah Butrymowicz’s “Concerns about Testing Accompany New Standards,” Hechinger Report 10/15/2013)
 As the Common Core Standards are put into place education will attempt to shift to critical thinking and deeper learning environments to get away from unpopular the teach-to-the-test culture. But some educators are worried the “drill and kill” culture will survive the shift to tougher standards.
As the Common Core Standards are put into place education will attempt to shift to critical thinking and deeper learning environments to get away from unpopular the teach-to-the-test culture. But some educators are worried the “drill and kill” culture will survive the shift to tougher standards.
Especially untenured teachers could very well continue to “teach to the test” since part of their evaluations are still subject to student test scores. In New York and Kentucky, two states that have tested their students on the new Common Core test, as expected test scores went down.
The new computer-based assessments aligned to the new standards are intended to test deeper understanding of concepts. In New York, the new tests are supposed to replace the Pearson exams statewide. The results from the tests will be included in teacher evaluations for all third- to eighth-grade math and English teachers.
PARCC test-makers say the online format allows them to go beyond the constraints of traditional multiple-choice bubble tests but they don’t know yet if the new test will be more difficult that the tests they are replacing. But they do claim that the new tests are being designed so that it’s impossible to teach to them. Students will have to learn a skill like reading a passage and extract evidence.
In the sample questions released by PARCC, students write short answers to some questions, such as writing a topic sentence for a paragraph or explaining their answer to a math problem. One sample task for fourth grade students is to have them write an essay comparing characters from two readings and prompting them to explain how the thoughts, words and/or actions of the character help the student understand what the character is like. Students will be scored between zero and four on such questions based on the clarity and grammar of their answer, as well as on how accurately and well they refer to the text.
Another sample item requires students to create a summary of a story by choosing three sentences from a list of eight and dragging them into a box to allow students to show their whole range of knowledge in the way that a multiple-choice test can’t.
But practice tests and examples published so far suggest that parts of the new tests won’t deviate far from the traditional format. PARCC’s sample literary analysis task for fourth grade, for example, asks multiple-choice questions such as, “Which statement best expresses the themes of the story?”
A policy analyst at the Stanford Center for Opportunity Policy in Education said the move to tests with performance tasks was promising, but not enough to realize the ultimate goals of the Common Core. They are basically standardized tests with some open-ended questions, so they do allow students to apply the skills that they have, but in a bounded environment.
It is hoped that policymakers will acknowledge that standardized test scores are imperfect measures of what students are supposed to learn under the new standards. Common Core has standards of speaking skills for each grade, for instance, which can’t be measured with multiple choice questions or essays. Students should be expected to do well on the test, but, at this stage, the tests are incomplete.
PARCC will offer two end-of-year tests, plus an optional diagnostic test for the beginning of the year and an optional midterm exam to help teachers measure student progress throughout the year. Critics worry the extra tests will exacerbate test prep, as teachers will take extra care to cover the items they know will be tested. Students will be sitting at computer terminals practicing their test-taking skills.
Since computerized assessments could be a financial burden for many rural New York’s school districts with limited Internet connectivity PARCC is considering offering a pencil and paper test in 2014-2015 to states that aren’t prepared for online testing, but ultimately districts will be expected to be able to test on computers.
The switch is seen as an unfunded mandate. Computer-based assessment is smart, it’s strategic, but it’s not free. It’s a question of where many of the school districts are going to be getting that money.
COMPUTER AIDED ASSESSMENT
Computer Aided Assessment, also known as E-assessment, ranges from automated multiple-choice tests to more sophisticated systems is becoming more common and is the basis of the new Common Core Standards assessment platform. Assessment software has a primary purpose of assessing and testing students in a virtual environment. It allows students to complete tests and examinations using a computer or a laptop, usually networked. The software then scores each test transcript and outputs results for each student. With some systems feedback can be geared towards a student’s specific mistakes or the computer can guide the student through a series of questions adapting to what the student appears to have learned or not learned.
Assessment software is available in various delivery methods, the most popular being self-hosted software, online software and hand-held voting systems. Proprietary software and open-source software systems are available. While technically falling into the Courseware category, “Skill” evaluation lab is an example for Computer-based assessment software with PPA-2 (Plan, Prove, and Assess) methodology to create and conduct computer based online examination.
The best examples follow a formative assessment structure and are called “Online Formative Assessment.” This involves making an initial formative assessment by sifting out the incorrect answers. The teacher will then explain what the pupil should have done with each question. It will then give the pupil at least one practice at each slight variation of sifted out questions. This is the formative learning stage. The next stage is to make a summative assessment by a new set of questions only covering the topics previously taught.
Learning design is the type of activity enabled by software that supports sequences of activities that can be both adaptive and collaborative. The IMS Learning Design specification is intended as a standard format for learning designs, and IMS LD Level A is supported in LAMS V2. eLearning has been replacing the traditional settings due to its cost effectiveness.
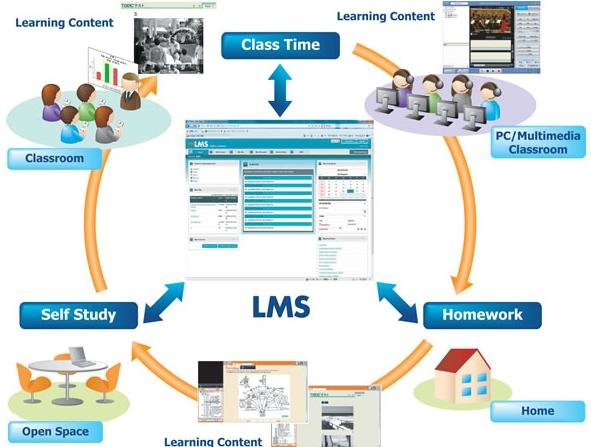 A Learning Management System (LMS) is software used for delivering, tracking and managing training/education. LMSs range from systems for managing training/educational records to software for distributing courses over the Internet and offering features for online collaboration.
A Learning Management System (LMS) is software used for delivering, tracking and managing training/education. LMSs range from systems for managing training/educational records to software for distributing courses over the Internet and offering features for online collaboration.
A Learning Content Management System (LCMS) is software for author content (courses, reusable content objects). An LCMS may be solely dedicated to producing and publishing content that is hosted on an LMS, or it can host the content itself.
A LMS allows for teachers and administrators to track attendance, time on task, and student progress. LMS also allows for not only teachers and administrators to track these variables but parents and students as well. Parents can log on to the LMS to track grades. Students log on to the LMS to submit homework and to access the course syllabus and lessons.
Moodle is an example of open-source software with an assessment component that is gaining popularity. Other popular international assessment systems include QuestionMark and EvaluNet XT.
RUBRICS ASSESSMENTS
Introduction
Often teachers have tried to grade students’ book tasks or other open-ended oral or written projects, and not known if they have graded them accurately? Could the teacher justify the grade if necessary? Would another teacher give the same grade? In other words, how reliable is a teacher assessment?
Can a teacher clearly evaluate their set goals using this task? Do these criteria reflect quality performance on this task? In other words, is the teacher’s assessment valid?
Having well-defined rubrics increases the validity and reliability of assessments. 
What are Rubrics?
A rubric is a scoring tool outlining required criteria for a piece of work, or what is important to assess. It also indicates the weighting that has been determined for each criterion, based on its relative importance to the overall task, and describes what the performance would look like at different quality levels. If the students receive this before beginning the task, they can more easily internalize the criteria, understand how they will be assessed and thus the performance level they should be striving for. Ideally, teachers develop this together with students, though it can be prepared by the teacher and given to the students for comments before they begin the task.
A checklist or assessment list is a simpler version of a rubric, specifying the criteria. It only gives the highest level of performance, not all the performance levels.
Unlike a traditional grade, which summarizes all aspects of students’ performance in a single number, letter or word, a rubric provides information on students’ performance on each of the criteria. This gives a profile of students’ ability, for formative and summative purposes.
Advantages of Using Rubrics in Assessment
Rubrics can improve and monitor students’ performance, by clarifying teacher expectations. Rubrics require the teacher to clarify his/her criteria and help define “quality” (i.e., what the teacher expects to see in the final product).
Rubrics can be used as a guide for self/peer assessment. They promote students’ awareness of the criteria used in assessing performance. When the students want to ensure they are meeting the teacher’s expectations, they can assess their work using rubrics or request feedback from peers, based on these expectations.
Rubrics increase validity, reliability and fairness in scoring. They provide for more objective and consistent assessment. As criteria relevant to the task are clearly defined, similar scores will be given no matter who is evaluating the work.
Rubrics provide a profile of students’ performance, describing strengths and weaknesses. This is due to the detailed description of the performance levels. The teacher will underline or highlight those parts of the description which apply to the student’s work.
Rubrics reduce the amount of time spent by teachers on evaluating students’ work. Once the assessment tool has been designed, it can efficiently grade even the longest project.
Rubrics accommodate heterogeneous classes. All levels are included in the performance descriptions. In fact, the more detailed they are, the better they cover the students’ varying levels. Students can strive to improve performance, as the requirements for doing so are clear. Rubrics encourage those students who may be weak in some criteria but talented in others, since they will not just be evaluated by a low overall numerical grade.
Rubrics make teachers and students accountable and aware of the learning objectives.
The teacher will be able to justify the grade clearly, with reference to the criteria. Moreover, involvement of students empowers them, leading to more focused and self-directed learning.
Rubrics are easy to understand and use. They can be referred to in parent-teacher meetings and student-teacher conferences where performance is discussed.
For more on rubrics see: Assessment Rubrics
STANDARDIZED TESTS
A standardized test is a test that is administered and scored in a consistent, or “standard”, manner. Standardized tests are designed in such a way that the questions, conditions for administering, scoring procedures, and interpretations are consistent and are administered and scored in a predetermined, standard manner.
Any test in which the same test is given in the same manner to all test takers is a standardized test. Standardized tests need not be “high-stakes tests,” “time-limited tests,” or “multiple-choice tests.” The opposite of a standardized test is a “non-standardized test.” Non-standardized testing gives significantly different tests to different test takers, or gives the same test under significantly different conditions (e.g., one group is permitted far less time to complete the test than the next group), or evaluates them differently (e.g., the same answer is counted right for one student, but wrong for another student).
Standardized tests are perceived as being fairer than non-standardized tests. The consistency also permits more reliable comparison of outcomes across all test takers.
HISTORY of STUDENT TESTING
China: Imperial Examination
 The earliest evidence of standardized testing was in China where the imperial examinations” covered thee “Six Arts” which included music, archery and horsemanship, arithmetic, writing, and knowledge of the rituals and ceremonies of both public and private parts. Later, the studies (military strategies, civil law, revenue and taxation, agriculture and geography) were added to the testing. In this form, the examinations were institutionalized during the 6th century CE, under the Sui Dynasty.
The earliest evidence of standardized testing was in China where the imperial examinations” covered thee “Six Arts” which included music, archery and horsemanship, arithmetic, writing, and knowledge of the rituals and ceremonies of both public and private parts. Later, the studies (military strategies, civil law, revenue and taxation, agriculture and geography) were added to the testing. In this form, the examinations were institutionalized during the 6th century CE, under the Sui Dynasty.
Britain
Standardized testing was introduced into Europe in the early 19th century, modeled on the Chinese mandarin examinations, through the advocacy of British colonial administrators, the most “persistent” of which was Britain’s consul in Guangzhou, China. Thomas Taylor Meadows warned of the collapse of the British Empire if standardized testing was not implemented throughout the empire immediately.
Prior to their adoption, standardized testing was not traditionally a part of Western pedagogy; based on the sceptical and open-ended tradition of debate inherited from Ancient Greece, Western academia favored non-standardized assessments using essays written by students. It is because of this that the first European implementation of standardized testing did not occur in Europe proper, but in British India. Inspired by the Chinese use of standardized testing in the early 19th century, British company managers hired and promoted employees based on competitive examinations in  order to prevent corruption and favoritism. This practice of standardized testing was later adopted in the late 19th century by the British mainland. The parliamentary debates that ensued made many references to the “Chinese mandarin system.”
order to prevent corruption and favoritism. This practice of standardized testing was later adopted in the late 19th century by the British mainland. The parliamentary debates that ensued made many references to the “Chinese mandarin system.”
It was from Britain that standardized testing spread not only throughout the British Commonwealth, but to Europe and then America. Its spread was fueled by the Industrial Revolution. Given the large number of school students during and after the industrial revolution when compulsory education laws increased student populations, open-ended assessment of all students decreased. Moreover, the lack of a standardized process introduces a substantial source of measurement error, as graders might show favoritism or might disagree with each other about the relative merits of different answers.
More recently, it has been shaped in part by the ease and low cost of grading of multiple-choice tests by computer. Grading essays by computer is more difficult, but is also done. In other instances, essays and other open-ended responses are graded according to a pre-determined assessment rubric (In education terminology, scoring rubric means “a standard of performance for a defined population”) by trained graders.
United States
 The use of standardized testing in the United States is a 20th-century phenomenon with its origins in World War I and the Army Alpha and Beta tests developed by Robert Yerkes and colleagues.
The use of standardized testing in the United States is a 20th-century phenomenon with its origins in World War I and the Army Alpha and Beta tests developed by Robert Yerkes and colleagues.
In the United States, the need for the federal government to make meaningful comparisons across a highly de-centralized (locally controlled) public education system has also contributed to the debate about standardized testing, including the Elementary and Secondary Education Act of 1965 that required standardized testing in public schools. US Public law 107-110, known as the No Child Left Behind Act 0d 2001 further ties public school funding to standardized testing.
DESIGN AND SCORING
Some standardized testing uses multiple-choice tests, which are relatively inexpensive to score, but any form of assessment can be used.
 Standardized testing can be composed of multiple-choice, true-false, essay questions, authentic assessments, or nearly any other form of assessment. Multiple-choice and true-false items are often chosen because they can be given and scored inexpensively and quickly by scoring special answer sheets by computer or via computer-adaptive testing. Some standardized tests have short-answer or essay writing components that are assigned a score by independent evaluators who use rubrics and benchmark papers (examples of papers for each possible score) to determine the grade to be given to a response. Most assessments, however, are not scored by people; people are used to score items that are not able to be scored easily by computer (i.e., essays). For example, the “Graduate Record Exam” is a computer-adaptive assessment that requires no scoring by people (except for the writing portion).
Standardized testing can be composed of multiple-choice, true-false, essay questions, authentic assessments, or nearly any other form of assessment. Multiple-choice and true-false items are often chosen because they can be given and scored inexpensively and quickly by scoring special answer sheets by computer or via computer-adaptive testing. Some standardized tests have short-answer or essay writing components that are assigned a score by independent evaluators who use rubrics and benchmark papers (examples of papers for each possible score) to determine the grade to be given to a response. Most assessments, however, are not scored by people; people are used to score items that are not able to be scored easily by computer (i.e., essays). For example, the “Graduate Record Exam” is a computer-adaptive assessment that requires no scoring by people (except for the writing portion).
Scoring issues
Human scoring is often variable, which is why computer scoring is preferred when feasible. For example, some believe that poorly paid employees will score tests badly. Agreement between scorers can vary between 60 to 85 percent, depending on the test and the scoring session. Sometimes states pay to have two or more scorers read each paper; if their scores do not agree, then the paper is passed to additional scorers.
Open-ended components of tests are often only a small proportion of the test. Most commonly, a major test includes both human-scored and computer-scored sections.
Scores
There are two types of standardized “test score” interpretations: a “norm-referenced” score interpretation or a “criterion-referenced” score interpretation.
Norm-referenced score interpretations compare test-takers to a sample of peers. The goal is to rank students as being better or worse than other students. Norm-referenced test score interpretations are associated with traditional education. Students who perform better than others pass the test, and students who perform worse than others fail the test.
are associated with traditional education. Students who perform better than others pass the test, and students who perform worse than others fail the test.
Criterion-referenced score interpretations compare test-takers to a criterion (a formal definition of content), regardless of the scores of other examinees. These may also be described a standards-based assessment, as they are aligned with the standards-based education reform movement. Criterion-referenced score interpretations are concerned solely with whether or not this particular student’s answer is correct and complete. Under criterion-referenced systems, it is possible for all students to pass the test, or for all students to fail the test.
Either of these systems can be used in standardized testing. What is important to standardized testing is whether all students are asked equivalent questions, under equivalent circumstances, and graded equally. In a standardized test, if a given answer is correct for one student, it is correct for all students. Graders do not accept an answer as good enough for one student but reject the same answer as inadequate for another student.
STANDARDS
The considerations of “validity” and “reliability” typically are viewed as essential elements for determining the quality of any standardized test. However, professional and practitioner associations frequently have placed these concerns within broader contexts when developing standards and making overall judgments about the quality of any standardized test as a whole within a given context.
Evaluation Standards
In the field of evaluation, and in particular education evaluation, the Joint Committee on Standards for Education Evaluation has published three sets of standards for evaluations. The “Personnel Evaluation Standards”] was published in 1988, “The Program Evaluation Standards” (2nd edition) was published in 1994, and “The Student Evaluation Standards” was published in 2003.
Each publication presents and elaborates a set of standards for use in a variety of educational settings. The standards provide guidelines for designing, implementing, assessing and improving the identified form of evaluation. Each of the standards has been placed in one of four fundamental categories to promote educational evaluations that are proper, useful, feasible, and accurate. In these sets of standards, validity and reliability considerations are covered under the accuracy topic. For example, the student accuracy standards help ensure that student evaluations will provide sound, accurate, and credible information about student learning and performance.
Testing standards
In the “field of psychometrics,” the Standard for Educational and Psychological Testing place standards about validity and reliability, along with errors of measurement and issues related to the accommodation of “individuals with disabilities.” The third and final major topic covers standards related to testing applications, credentialing, plus testing in program evaluation and public policy.
Advantages
One of the main advantages of standardized testing is that the results can be empirically documented; therefore, the test scores can be shown to have a relative degree of “validity and reliability” as well as results which are generalizable and replicable. This is often contrasted with grades on a school transcript, which are assigned by individual teachers. It may be difficult to account for  differences in educational culture across schools, difficulty of a given teacher’s curriculum, differences in teaching style, and techniques and biases that affect grading. This makes standardized tests useful for admissions purposes in higher education, where a school is trying to compare students from across the nation or across the world.
differences in educational culture across schools, difficulty of a given teacher’s curriculum, differences in teaching style, and techniques and biases that affect grading. This makes standardized tests useful for admissions purposes in higher education, where a school is trying to compare students from across the nation or across the world.
Another advantage is “aggregation.” A well designed standardized test provides an assessment of an individual’s mastery of a domain of knowledge or skill which at some level of aggregation will provide useful information. That is, while individual assessments may not be accurate enough for practical purposes, the mean scores of classes, schools, branches of a company, or other groups may well provide useful information because of the reduction of error accomplished by increasing the sample size.
Standardized tests, which by definition give all test-takers the same test under the same (or reasonably equal) conditions, are also perceived as being more fair than assessments that use different questions or different conditions for students according to their race, socioeconomic status, or other considerations.
DISADVANTAGES AND CRITICISM
“Standardized tests can’t measure initiative, creativity, imagination, conceptual thinking, curiosity, effort, irony, judgment, commitment, nuance, good will, ethical reflection, or a host of other valuable dispositions and attributes. What they can measure and count are isolated skills, specific facts and function, content knowledge, the least interesting and least significant aspects of learning.” Bill Ayers
Bill Ayers
Standardized tests are useful tools for assessing student achievement, and can be used to focus instruction on desired outcomes, such as reading and math skills. However, critics feel that overuse and misuse of these tests harms teaching and learning by narrowing the curriculum. According to the group Fair Test when standardized tests are the primary factor in accountability, schools use the tests to define curriculum and focus instruction. Critics say that “teaching to the test” disfavors higher-order learning. While it is possible to use a standardized test without letting its contents determine curriculum and instruction, frequently, what is not tested is not taught, and how the subject is tested often becomes a model for how to teach the subject.
Uncritical use of standardized test scores to evaluate teacher and school performance is inappropriate, because the students’ scores are influenced by three things: what students learn in school, what students learn outside of school, and the students’ innate intelligence. The school only has control over one of these three factors. Value-added modeling has been proposed to cope with this criticism by statistically controlling  for innate ability and out-of-school contextual factors. In a value-added system of interpreting test scores, analysts estimate an expected score for each student, based on factors such as the student’s own previous test scores, primary language, or socioeconomic status. The difference between the student’s expected score and actual score is presumed to be due primarily to the teacher’s efforts.
for innate ability and out-of-school contextual factors. In a value-added system of interpreting test scores, analysts estimate an expected score for each student, based on factors such as the student’s own previous test scores, primary language, or socioeconomic status. The difference between the student’s expected score and actual score is presumed to be due primarily to the teacher’s efforts.
Supporters of standardized testing respond that these are not reasons to abandon standardized testing in favor of either non-standardized testing or of no assessment at all, but rather criticisms of poorly designed testing regimes. They argue that testing does and should focus educational resources on the most important aspects of education — imparting a pre-defined set of knowledge and skills — and that other aspects are either less important, or should be added to the testing scheme.
In her book, Now You See It, Cathy Davidson criticizes standardized tests. She describes our youth as “assembly line kids on an assembly line model,” meaning the use of standardized test as a part of a one-size-fits-all educational model. She also criticizes the narrowness of skills being tested and labeling children without these skills as failures or as students with disabilities.
The following is an abstract from “The Wrong Villain: Critics should focus on Race to the Top not on Common Core.”
In Paige Jaeger’s School Library Journal article states that critic of CCSS are not focusing on the real target. They should instead be focusing on Race to the Top’s (RttT) $4.35 billion U.S. Department of Education’s competitive grant to reform schools by measuring student success and holding teachers and principals accountable as a strategy to close the achievement gap, and reforming curriculum.
The RttT has driven the ills of excessive testing; teacher measurement; data-archiving monsters that will track “achievement” by numbers using many days annually in formal assessment; and requiring monetary expenditures, which often are being administered Robin Hood style, on electronic devices or computers. This is what should be questioned.
All over the world, teachers are learning to repackage their curriculum so that students uncover and discover, rather than merely cover material. If the U.S. education system does not adapt, our students are likely to be standing behind a student from India or Turkey who has, according to Intel, learned “to lead and participate in the global economy.” While our students build travel brochures and call that endeavor research, international students assess the mortality rates in various countries and propose action plans for remediation. A Harvard review of the international educational assessment data warns, “The United States’ failure to educate its students leaves them unprepared to compete and threatens the country’s ability to thrive in a global economy.”
Our founding fathers believed that education should be for all, even for the impoverished–whom other countries may not be educating or testing. Until recently, we have done that better than most other nations. In an effort to remediate our international ranking, an independent organization examined shortcomings and strengths in our system. The result was the CCSS, intended to raise rigor, embed real-world relevance into our curriculum, and keep students on the same academic page regardless of their home state. When the anchor standards explicitly say to research, assess sources, and avoid plagiarism, we educators should rejoice. The CCSS authors correctly assessed this generation’s needs and supported a student-centered inquiry-based research model rather than a teacher-defined task.
What CCSS is not
The CC authors did not say that we needed a national testing behemoth and should spend $350 million to create and administer such animal. RttT identified the Common Core as the standards to adopt if states were going to compete for RttT monies.
In turn, new testing machines such as PARCC and Smarter Balance are trying to quantify all achievement by numerical measures. Experienced teachers believe assessment is vital to direct teaching and learning but are not convinced another set of tests is the answer. Experienced teachers feel that tests alone are not an accurate reflection of all progress and quality. They are concerned with what the assessments are not measuring. They may also comment that they would have rather seen the $350 million spent on competitive assessment grants allocated to books and materials for the classroom—to speak nothing of the technology being doled out as a panacea for poor scores. States are supposed to fold qualitative measures into their teacher assessment data, but many argue that qualitative measures cannot be “quantified” accurately.
SCORING INFORMATION LOSS
A test question might require a student to calculate the area of a triangle. Compare the information provided in these two answers.
Area = 7.5 cm2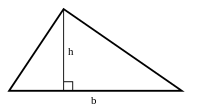
Base=5cm; Height=3cm
Area = 1/2(Base × Height)
Area = 1/2(5 cm × 3 cm)
Area = 7.5 cm2
The first shows scoring information loss. The teacher knows whether the student got the right answer, but does not know how the student arrived at the answer. If the answer is wrong, the teacher does not know whether the student was guessing, made a simple error, or fundamentally misunderstands the subject.
 When tests are scored right-wrong, an important assumption has been made about learning. The number of right answers or the sum of item scores (where partial credit is given) is assumed to be the appropriate and sufficient measure of current performance status. In addition, a secondary assumption is made that there is no meaningful information in the wrong answers.
When tests are scored right-wrong, an important assumption has been made about learning. The number of right answers or the sum of item scores (where partial credit is given) is assumed to be the appropriate and sufficient measure of current performance status. In addition, a secondary assumption is made that there is no meaningful information in the wrong answers.
In the first place, a correct answer can be achieved using memorization without any profound understanding of the underlying content or conceptual structure of the problem posed. Second, when more than one step for solution is required, there are often a variety of approaches to answering that will lead to a correct result. The fact that the answer is correct does not indicate which of the several possible procedures were used. When the student supplies the answer (or shows the work) this information is readily available from the original documents.
Second, if the wrong answers were blind guesses, there would be no information to be found among these answers. On the other hand, if wrong answers reflect interpretation departures from the expected one, these answers should show an ordered relationship to whatever the overall test is measuring. This departure should be dependent upon the level of psycholinguistic maturity of the student choosing or giving the answer in the vernacular in which the test is written.
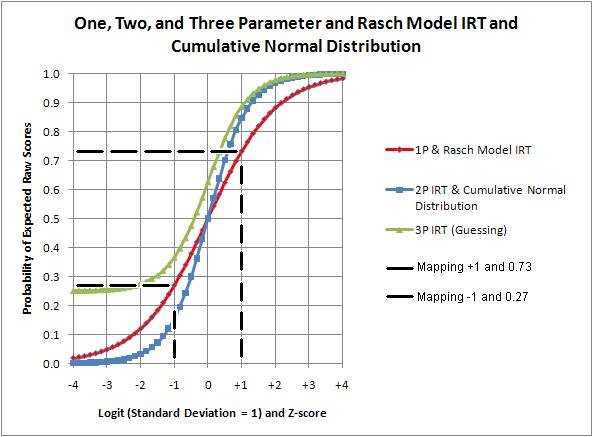 In this second case it should be possible to extract this order from the responses to the test items. Such extraction processes, the Rasch model for instance, are standard practice for item development among professionals. However, because the wrong answers are discarded during the scoring process, attempts to interpret these answers for the information they might contain is seldom undertaken.
In this second case it should be possible to extract this order from the responses to the test items. Such extraction processes, the Rasch model for instance, are standard practice for item development among professionals. However, because the wrong answers are discarded during the scoring process, attempts to interpret these answers for the information they might contain is seldom undertaken.
Third, although topic-based subtest scores are sometimes provided, the more common practice is to report the total score or a rescaled version of it. This rescaling is intended to compare these scores to a standard of some sort. This further collapse of the test results systematically removes all the information about which particular items were missed.
Thus, scoring a test right–wrong loses:
1) How students achieved their correct answers
2) What led them astray towards unacceptable answers
3) Where within the body of the test this departure from expectation occurred.
This commentary suggests that the current scoring procedure conceals the dynamics of the test-taking process and obscures the capabilities of the students being assessed. Current scoring practice oversimplifies these data in the initial scoring step. The result of this procedural error is to obscure of the diagnostic information that could help teachers serve their students better. It further prevents those who are diligently preparing these tests from being able to observe the information that would otherwise have alerted them to the presence of this error.
A solution to this problem, known as Response Spectrum Evaluation (RSE), is currently being developed that appears to be capable of recovering all three of these forms of information loss, while still providing a numerical scale to establish current performance status and to track performance change.
This RSE approach provides an interpretation of the thinking processes behind every answer (both the right and the wrong ones) that tells teachers how they were thinking for every answer they  provide. Among other findings, this chapter reports that the recoverable information explains between two and three times more of the test variability than considering only the right answers. This massive loss of information can be explained by the fact that the “wrong” answers are removed from the test information being collected during the scoring process and is no longer available to reveal the procedural error inherent in right-wrong scoring. The procedure bypasses the limitations produced by the linear dependencies inherent in test data.
provide. Among other findings, this chapter reports that the recoverable information explains between two and three times more of the test variability than considering only the right answers. This massive loss of information can be explained by the fact that the “wrong” answers are removed from the test information being collected during the scoring process and is no longer available to reveal the procedural error inherent in right-wrong scoring. The procedure bypasses the limitations produced by the linear dependencies inherent in test data.
Testing bias occurs when a test systematically favors one group over another even though both groups are equal on the trait the test measures. Critics allege that test makers and facilitators tend to represent a middle class, white background. Critics claim that standardized testing match the values, habits, and language of the test makers. However, being that most tests come from a white, middle-class background, it is important to note that the highest scoring groups are not people of that background, but rather tend to come from Asian populations.
Not all tests are well-written, for example, containing multiple-choice questions with ambiguous answers, or poor coverage of the desired curriculum. Some standardized tests include essay questions, and some have criticized the effectiveness of the grading methods. Recently, partial computerized grading of essays has been introduced for some tests, which is even more controversial.
EDUCATIONAL DECISIONS
Test scores are in some cases used as a sole, mandatory, or primary criterion for admissions or certification. For example, some U.S. states require high school graduation examinations. Adequate  scores on these exit exams are required for high school graduation. The General Education Development (GED) test is often used as an alternative to a high school diploma.
scores on these exit exams are required for high school graduation. The General Education Development (GED) test is often used as an alternative to a high school diploma.
Other applications include tracking (deciding whether a student should be enrolled in the “fast” or “slow” version of a course) and awarding scholarships. In the United States, many colleges and universities automatically translate scores on Advanced Placement tests into college credit, satisfaction of graduation requirements, or placement in more advanced courses. Generalized tests such as the SAT or GED are more often used as one measure among several, when making admissions decisions. Some public institutions have cutoff scores for the SAT, GPA, or class rank, for creating classes of applicants to automatically accept or reject.
Heavy reliance on standardized tests for decision-making is often controversial, for the reasons noted above. Critics often propose emphasizing cumulative or even non-numerical measures, such as classroom grades or brief individual assessments (written in prose) from teachers. Supporters argue that test scores  provide a clear-cut, objective standard that minimizes the potential for political influence or favoritism.
provide a clear-cut, objective standard that minimizes the potential for political influence or favoritism.
The National Academy of Sciences recommends that major educational decisions not be based solely on a test score. The use of minimum cut-scores for entrance or graduation does not imply a single standard, since test scores are nearly always combined with other minimal criteria such as number of credits, prerequisite courses, attendance, etc. Test scores are often perceived as the “sole criteria” simply because they are the most difficult, or the fulfillment of other criteria is automatically assumed. One exception to this rule is the GED, which has allowed many people to have their skills recognized even though they did not meet traditional criteria. Wikipedia
K-12 Testing and Assessment Standards Articles
No Test Left Behind: How Pearson Made a Killing on the US Testing Craze
Recent Comments